Note
This is a static copy of a Jupyter notebook.
You can access a live version allowing you to modify and execute the code using Binder.
6.3. Creating Visualizations with Matplotlib and Pandas¶
Matplotlib is a “Python 2D plotting library” for creating a wide range of data visualizations. Pandas bills itself as a “Python data analysis library.” Together, they provide a powerful toolkit for doing data science.
Each library is very powerful, and that means they can get complicated. Here, we will stick to a few specific tools each library provides in order to limit the complexity.
First, some imports.
The first imports one piece of Matplotlib and names it plt. This
is commonly done to make it faster to type (we’ll be using it and thus
typing it a lot). This will be our tool for creating and modifying
plots.
import matplotlib.pyplot as plt
The second imports pandas and names the whole library pd, again a
common short name used to make code slightly shorter and faster to type.
import pandas as pd
The following line is needed just to make pandas and matplotlib work together correctly when your data contain dates, which the example data in this notebook do.
pd.plotting.register_matplotlib_converters()
We’ll also run the following line of code to make the charts look a bit nicer than the defaults in Jupyter.
# For slightly nicer charts
plt.rcParams['figure.figsize'] = [10, 5]
plt.rcParams['figure.dpi'] = 150
6.3.1. Loading data with Pandas¶
We’ve seen and written code for reading data from files. It’s complicated, especially when we have to parse the data (converting strings to numbers and other data types) and filter it (dealing with missing or incorrect values, for example). Because this is a common task, though, pandas provides tools that handle many common situations.
In our case, we will be reading data from .csv files (storing data
in the Comma-separated
values
format), and pandas provides the pd.read_csv() method. We give it a
filename as an argument. Here, we’re loading data from the Broadway
dataset from CORGIS.
Because one of the columns contains dates, we tell pandas to parse the
dates by giving the parse_dates argument a list containing that
column’s name. Remember that all of the data in a file is just one big
string. And when pandas reads a CSV file, it reads all of the values as
strings initially. It automatically detects numbers and converts them
into int or float data types, but dates are often just left as strings.
We have to tell it explicitly that we want to convert those string
values into a data type that represents a date, not just a string of
characters.
The pd.read_csv() method returns a dataframe. We’ll evaluate the
dataframe variable by itself on the last line of the cell to see what it
is.
df = pd.read_csv("broadway.csv", parse_dates=["Full"])
df
| Attendance | Capacity | Day | Full | Gross | Gross Potential | Month | Name | Performances | Theatre | Type | Year | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5500 | 88 | 26 | 1990-08-26 | 134456 | 0 | 8 | Tru | 8 | Booth | Play | 1990 |
| 1 | 1737 | 100 | 24 | 1991-03-24 | 100647 | 0 | 3 | Miss Saigon | 0 | Broadway | Musical | 1991 |
| 2 | 12160 | 100 | 31 | 1991-03-31 | 634424 | 0 | 3 | Miss Saigon | 0 | Broadway | Musical | 1991 |
| 3 | 13921 | 100 | 7 | 1991-04-07 | 713353 | 0 | 4 | Miss Saigon | 0 | Broadway | Musical | 1991 |
| 4 | 10973 | 90 | 14 | 1991-04-14 | 573981 | 0 | 4 | Miss Saigon | 4 | Broadway | Musical | 1991 |
| 5 | 14076 | 101 | 21 | 1991-04-21 | 706793 | 0 | 4 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 6 | 14065 | 101 | 28 | 1991-04-28 | 714968 | 0 | 4 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 7 | 14064 | 101 | 5 | 1991-05-05 | 730765 | 0 | 5 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 8 | 13896 | 100 | 12 | 1991-05-12 | 766713 | 0 | 5 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 9 | 13738 | 99 | 19 | 1991-05-19 | 763332 | 0 | 5 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 10 | 13897 | 100 | 26 | 1991-05-26 | 769137 | 0 | 5 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 11 | 14016 | 101 | 2 | 1991-06-02 | 774412 | 0 | 6 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 12 | 14088 | 101 | 9 | 1991-06-09 | 771767 | 0 | 6 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 13 | 14088 | 101 | 16 | 1991-06-16 | 770819 | 0 | 6 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 14 | 14088 | 101 | 23 | 1991-06-23 | 771192 | 0 | 6 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 15 | 14088 | 101 | 30 | 1991-06-30 | 777088 | 0 | 6 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 16 | 14088 | 101 | 7 | 1991-07-07 | 779802 | 0 | 7 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 17 | 14084 | 101 | 14 | 1991-07-14 | 782314 | 0 | 7 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 18 | 14088 | 101 | 21 | 1991-07-21 | 781413 | 0 | 7 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 19 | 14088 | 101 | 28 | 1991-07-28 | 786612 | 0 | 7 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 20 | 14088 | 101 | 4 | 1991-08-04 | 782060 | 0 | 8 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 21 | 14088 | 101 | 11 | 1991-08-11 | 781332 | 0 | 8 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 22 | 14088 | 101 | 18 | 1991-08-18 | 784392 | 0 | 8 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 23 | 14088 | 101 | 25 | 1991-08-25 | 786452 | 0 | 8 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 24 | 14088 | 101 | 1 | 1991-09-01 | 786995 | 0 | 9 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 25 | 14088 | 101 | 8 | 1991-09-08 | 783503 | 0 | 9 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 26 | 14088 | 101 | 15 | 1991-09-15 | 781614 | 0 | 9 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 27 | 14088 | 101 | 22 | 1991-09-22 | 780148 | 0 | 9 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 28 | 14088 | 101 | 29 | 1991-09-29 | 776172 | 0 | 9 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| 29 | 14088 | 101 | 6 | 1991-10-06 | 775124 | 0 | 10 | Miss Saigon | 8 | Broadway | Musical | 1991 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 31266 | 13558 | 100 | 7 | 2016-08-07 | 2292428 | 97 | 8 | The Lion King | 8 | Minskoff | Musical | 2016 |
| 31267 | 10475 | 82 | 7 | 2016-08-07 | 961265 | 63 | 8 | The Phantom Of The Opera | 8 | Majestic | Musical | 2016 |
| 31268 | 8128 | 97 | 7 | 2016-08-07 | 996212 | 98 | 8 | Waitress | 8 | Brooks Atkinson | Musical | 2016 |
| 31269 | 15295 | 94 | 7 | 2016-08-07 | 1927412 | 96 | 8 | Wicked | 9 | Gershwin | Musical | 2016 |
| 31270 | 13288 | 96 | 14 | 2016-08-14 | 1663119 | 90 | 8 | Aladdin | 8 | New Amsterdam | Musical | 2016 |
| 31271 | 3877 | 64 | 14 | 2016-08-14 | 314205 | 38 | 8 | An Act Of God 2016 | 8 | Booth | Play | 2016 |
| 31272 | 9111 | 68 | 14 | 2016-08-14 | 687762 | 47 | 8 | An American In Paris | 8 | Palace | Musical | 2016 |
| 31273 | 6829 | 83 | 14 | 2016-08-14 | 728242 | 72 | 8 | Beautiful | 8 | Stephen Sondheim | Musical | 2016 |
| 31274 | 10292 | 94 | 14 | 2016-08-14 | 1108909 | 78 | 8 | Cats 2016 | 8 | Neil Simon | Musical | 2016 |
| 31275 | 6929 | 80 | 14 | 2016-08-14 | 571623 | 60 | 8 | Chicago | 8 | Ambassador | Musical | 2016 |
| 31276 | 8632 | 63 | 14 | 2016-08-14 | 652283 | 42 | 8 | Fiddler On The Roof 2015 | 8 | Broadway | Musical | 2016 |
| 31277 | 8775 | 73 | 14 | 2016-08-14 | 628895 | 43 | 8 | Finding Neverland | 8 | Lunt-Fontanne | Musical | 2016 |
| 31278 | 4966 | 84 | 14 | 2016-08-14 | 379242 | 48 | 8 | Fun Home | 8 | Circle In The Square | Musical | 2016 |
| 31279 | 10756 | 102 | 14 | 2016-08-14 | 2045095 | 105 | 8 | Hamilton | 8 | Richard Rodgers | Musical | 2016 |
| 31280 | 5991 | 61 | 14 | 2016-08-14 | 530413 | 46 | 8 | Jersey Boys | 8 | August Wilson | Musical | 2016 |
| 31281 | 7117 | 62 | 14 | 2016-08-14 | 651433 | 50 | 8 | Kinky Boots | 8 | Al Hirschfeld | Musical | 2016 |
| 31282 | 11244 | 100 | 14 | 2016-08-14 | 1035397 | 88 | 8 | Les Misrables '14 | 8 | Imperial | Musical | 2016 |
| 31283 | 10341 | 90 | 14 | 2016-08-14 | 876824 | 73 | 8 | Matilda | 8 | Shubert | Musical | 2016 |
| 31284 | 7585 | 58 | 14 | 2016-08-14 | 703403 | 45 | 8 | On Your Feet! | 8 | Marquis | Musical | 2016 |
| 31285 | 11360 | 75 | 14 | 2016-08-14 | 997867 | 55 | 8 | Paramour | 8 | Lyric | Musical | 2016 |
| 31286 | 11342 | 95 | 14 | 2016-08-14 | 1160694 | 76 | 8 | School Of Rock | 8 | Winter Garden | Musical | 2016 |
| 31287 | 7239 | 67 | 14 | 2016-08-14 | 584022 | 46 | 8 | Something Rotten! | 8 | St. James | Musical | 2016 |
| 31288 | 8731 | 102 | 14 | 2016-08-14 | 1305962 | 97 | 8 | The Book Of Mormon | 8 | Eugene O'Neill | Musical | 2016 |
| 31289 | 7367 | 88 | 14 | 2016-08-14 | 718400 | 70 | 8 | The Color Purple 2015 | 8 | Jacobs | Musical | 2016 |
| 31290 | 6407 | 79 | 14 | 2016-08-14 | 464058 | 54 | 8 | The Curious Incident Of The Dog In The Night-Time | 8 | Ethel Barrymore | Play | 2016 |
| 31291 | 7234 | 87 | 14 | 2016-08-14 | 603770 | 62 | 8 | The Humans | 8 | Schoenfeld | Play | 2016 |
| 31292 | 13485 | 99 | 14 | 2016-08-14 | 2233894 | 97 | 8 | The Lion King | 8 | Minskoff | Musical | 2016 |
| 31293 | 10966 | 85 | 14 | 2016-08-14 | 999632 | 66 | 8 | The Phantom Of The Opera | 8 | Majestic | Musical | 2016 |
| 31294 | 8058 | 96 | 14 | 2016-08-14 | 990128 | 97 | 8 | Waitress | 8 | Brooks Atkinson | Musical | 2016 |
| 31295 | 13804 | 95 | 14 | 2016-08-14 | 1779664 | 100 | 8 | Wicked | 8 | Gershwin | Musical | 2016 |
31296 rows × 12 columns
The dataframe (which we named df) is a table with 31,296 rows and 12
columns containing all of the data from the CSV file. It has parsed out
the column names, given each row an index (counting from 0), parsed
strings into numbers in certain columns automatically, and given us a
single object (the df variable) that we can use to access all of
this.
6.3.2. Plotting data from a dataframe¶
We can use a dataframe as a source of data for Matplotlib’s plotting
functions. Instead of giving the plotting functions lists of values, we
give it the entire dataframe (as an argument data=[...]) and specify
which columns we want to plot by name.
For example, to make a scatter plot with the Attendance values on the x
axis and Gross (revenue) values on the y axis, we can call
plt.scatter() with x="Attendance", y="Gross", and
data=df.
plt.scatter(x="Attendance", y="Gross", data=df)
plt.xlabel("Attendance")
plt.ylabel("Gross Revenue")
plt.title("Attendance vs Gross Revenue")
plt.show()
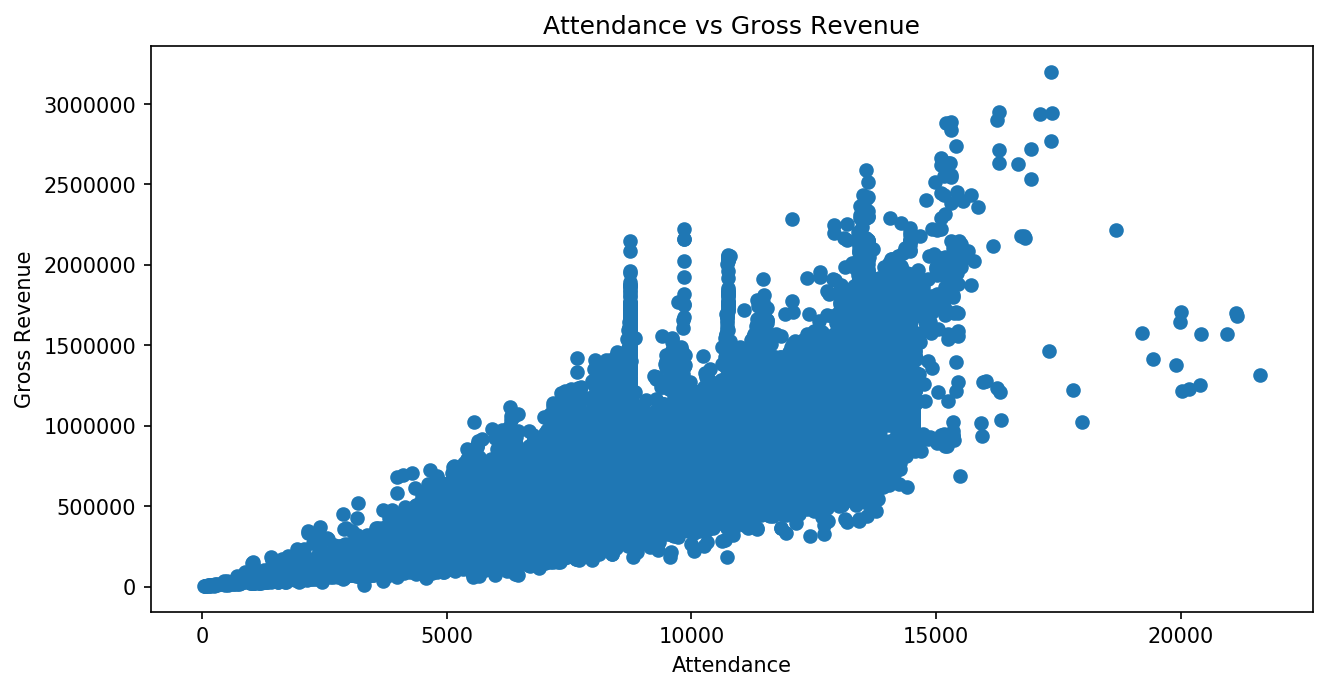
This particular plot has 31 thousand markers and a lot of overlap, which
makes it difficult to see what is going on in the giant “blob” of
overlapping markers. To make a better, more useful visualization, we can
set alpha=0.1 to make the markers semi-transparent and s=2 to
reduce the size of each marker.
plt.scatter(x="Attendance", y="Gross", data=df, alpha=0.1, s=2)
plt.xlabel("Attendance")
plt.ylabel("Gross Revenue")
plt.title("Attendance vs Gross Revenue")
plt.show()
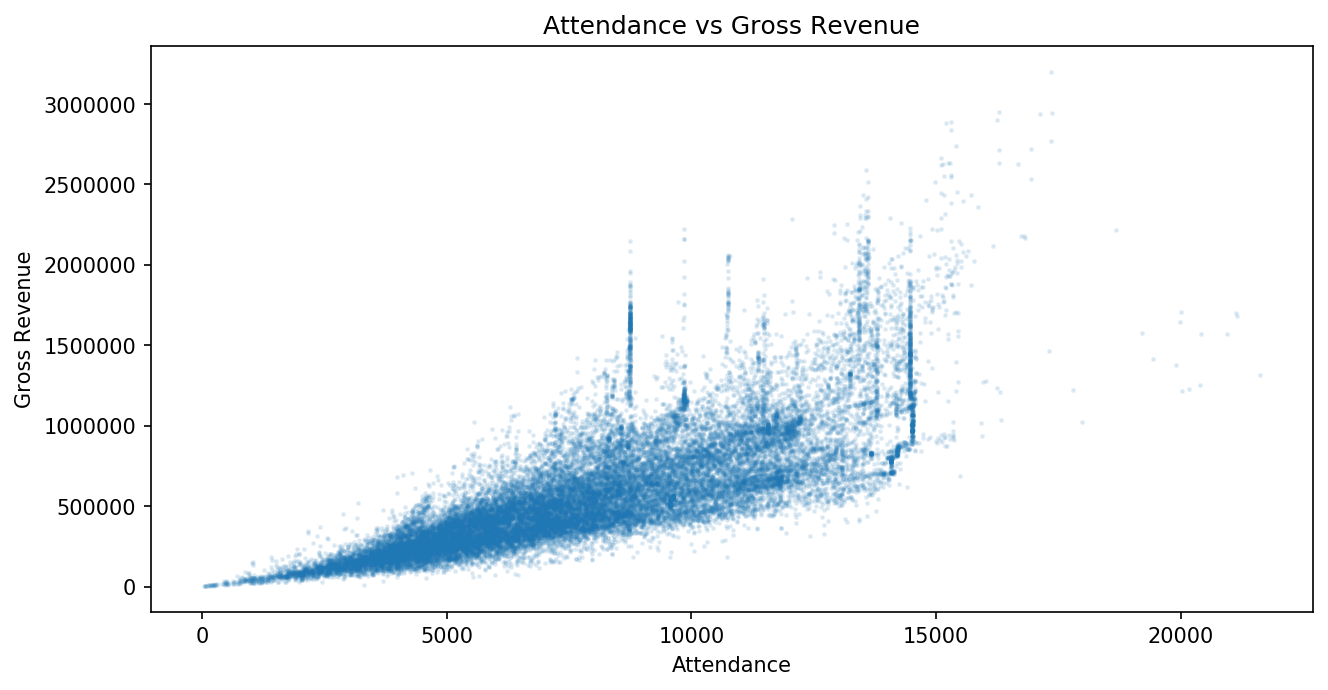
6.3.3. Histogram¶
Again, we can specify the data we want to plot in a histogram by giving
the plt.hist() method a column label for its x argument and a
dataframe for the data argument.
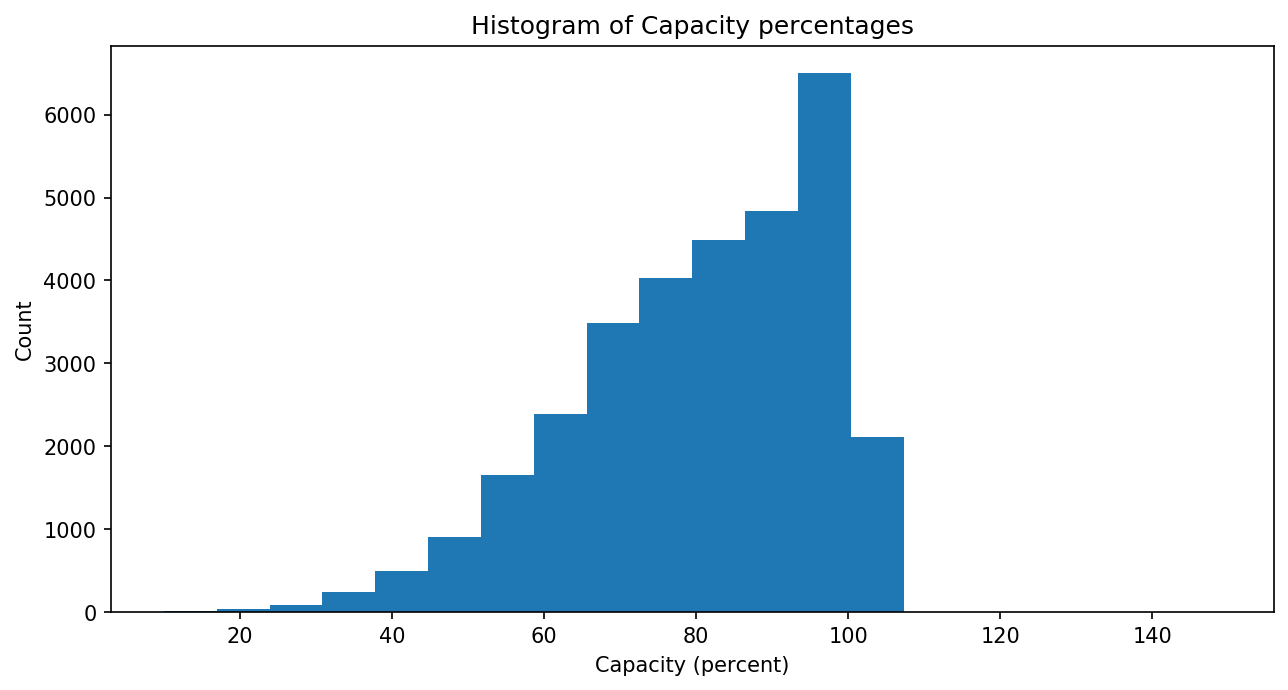
plt.hist(x="Capacity", data=df)
plt.xlabel("Capacity (percent)")
plt.ylabel("Count")
plt.title("Histogram of Capacity percentages")
plt.show()

This plot looks odd. The x-axis extends to 800 and beyond, even though it should be representing a capacity percentage that shouldn’t go much above 100%. But there are a few rows in the data that contain odd capacity values well above 100%. We might choose to visualize the “normal” capacity values alone by filtering out the odd ones.
To do this, we can use the dataframe’s .query() method. This method
takes a string as an argument that it will interpret as a condition. The
method returns a new dataframe containing any rows for which that
condition is True. We store the return value in a new dataframe variable
(here, df_filtered_cap) and use that as our data source for the
plt.hist() method.
We’ve also changed the number of bins here to get a slightly more granular breakdown of the data.
df_filtered_cap = df.query('Capacity < 200')
plt.hist(x="Capacity", data=df_filtered_cap, bins=20)
plt.xlabel("Capacity (percent)")
plt.ylabel("Count")
plt.title("Histogram of Capacity percentages")
plt.show()
6.3.4. Line Chart¶
For line charts, again we call Matplotlib’s plotting function
(plt.plot() in this case), specifying column labels as the first two
arguments (for the x and y axis) and a dataframe as a data source using
the data argument.
[You may have noticed by now that the plt.plot() function is the one
charting function for which we do not write x= and y= before
the x and y arguments. The other functions allow it, and doing so is
best for writing clear code, but if you try to add those for
plt.plot(), you will get an error. So do use the x=, etc.
argument labels in other chart drawing functions for clarity, but leave
them out with plt.plot().]
Here, we want to compare revenue over time for Rent and The Lion
King, so we make two new dataframes each containing just the data for
one of those shows. Again, we can use the .query() dataframe method
to do this. Note how we have to specify the string value "Rent" or
"The Lion King" inside the query string itself, so we use two
different types of quotation marks.
df_rent = df.query('Name == "Rent"')
df_lionking = df.query('Name == "The Lion King"')
plt.plot('Full', 'Gross', data=df_rent)
plt.plot('Full', 'Gross', data=df_lionking)
plt.xlabel("Date")
plt.ylabel("Gross Revenue (weekly, $)")
plt.legend(["Rent", "The Lion King"])
plt.title("Weekly Gross Revenue")
plt.show()
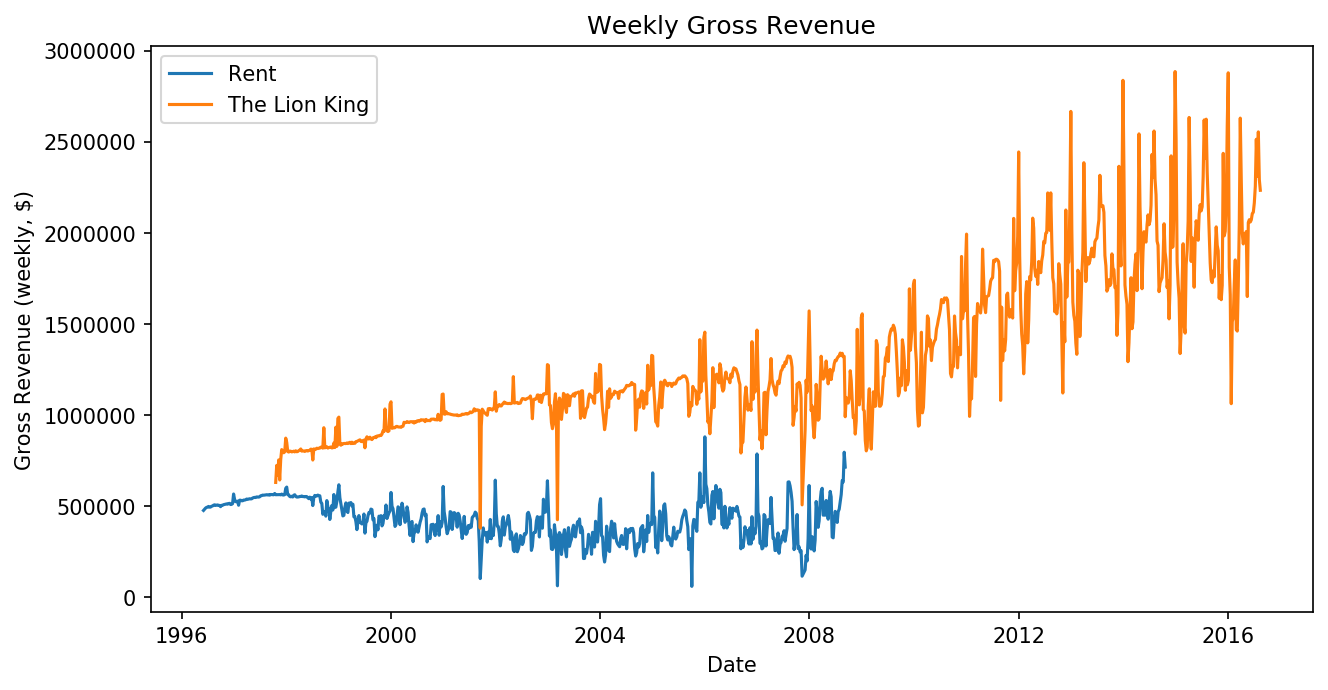
6.3.5. Scatter Plot¶
We can use those same dataframes (with data from Rent and The Lion King) to make a scatter plot investigating their revenue further..
Here, we plot attendance vs revenue for each show in one combined plot.
We’ve set alpha and s arguments for each to make individual data
points easier to see.
plt.scatter(x='Attendance', y='Gross', data=df_rent, alpha=0.25, s=5)
plt.scatter(x='Attendance', y='Gross', data=df_lionking, alpha=0.25, s=5)
plt.xlabel("Attendance (weekly)")
plt.ylabel("Gross Revenue (weekly, $)")
plt.legend(["Rent", "The Lion King"])
plt.title("Attendance vs Revenue")
plt.show()
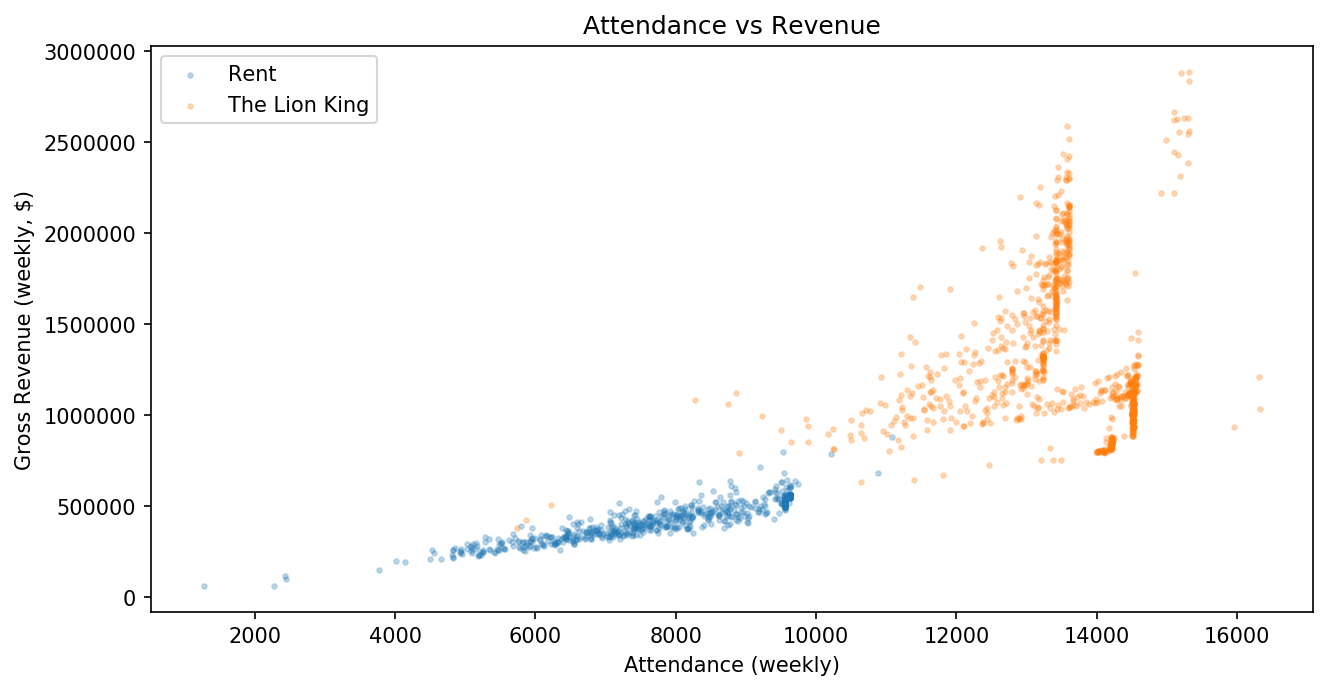
6.3.6. Bar Chart¶
Bar charts are often used for displaying just a few categories together at once. A plot with 31 thousand bars is not very useful, for example. Very often, then, we will group rows across a table by some characteristic and aggregate data across multiple rows for each group.
For example, we might want to see the total gross revenue for all Broadway shows, grouped by type of show. Pandas gives us functions to do this. We’ll show you how this works in a few steps.
First, we can call .groupby() on a dataframe, specifying a column
name as an argument. This will group all of the rows based on unique
values in that column. The “Type” column in our data has three values
(“Musical”, “Play”, and “Special”), and we’ll end up with three groups.
df_groupby_type = df.groupby("Type")
type(df_groupby_type)
pandas.core.groupby.generic.DataFrameGroupBy
This gives us a DataFrameGroupBy object. We still need to do the
aggregation. Sums and averages (means) are commonly used here. We’ll
take a sum across each group.
df_groupby_type_sums = df_groupby_type.sum()
df_groupby_type_sums
| Attendance | Capacity | Day | Gross | Gross Potential | Month | Performances | Year | |
|---|---|---|---|---|---|---|---|---|
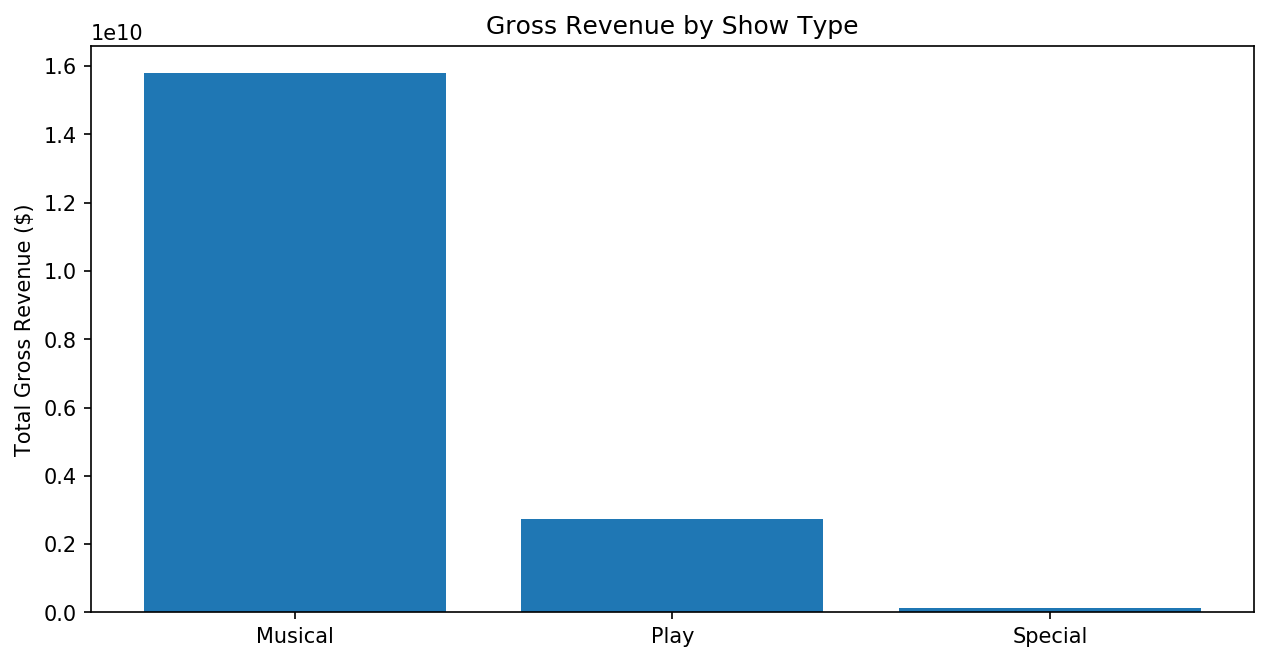
| Type | ||||||||
| Musical | 205909883 | 1882287 | 354478 | 15792740093 | 1488758 | 147858 | 170514 | 45237842 |
| Play | 43056274 | 618454 | 132291 | 2737985361 | 446950 | 53389 | 53878 | 16858645 |
| Special | 1731171 | 26064 | 5231 | 123844139 | 17289 | 2460 | 1716 | 679381 |
We get back a new dataframe with one row per Type value. Each column now contains the sum of that column’s values across all of the rows that had the matching type. For example, here we can see that there are 1716 performances in total across all “Special” shows.
We need to take one last step to make this useable for plotting a bar
chart. We need to turn the index (the name assigned to each row)
back into a data column. We use the .reset_index() method for
that:
df_groupby_type_sums = df_groupby_type_sums.reset_index()
df_groupby_type_sums
| Type | Attendance | Capacity | Day | Gross | Gross Potential | Month | Performances | Year | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Musical | 205909883 | 1882287 | 354478 | 15792740093 | 1488758 | 147858 | 170514 | 45237842 |
| 1 | Play | 43056274 | 618454 | 132291 | 2737985361 | 446950 | 53389 | 53878 | 16858645 |
| 2 | Special | 1731171 | 26064 | 5231 | 123844139 | 17289 | 2460 | 1716 | 679381 |
Notice how we now have a “Type” column, and each row is just given a number index now? This will let us use the “Type” data on one of our plot axes.
Finally, we can simplify all of the above steps into one line. Because each of the methods we called returns a new object, we can chain the method calls like this:
df_groupby_type_sums = df.groupby("Type").sum().reset_index()
df_groupby_type_sums
| Type | Attendance | Capacity | Day | Gross | Gross Potential | Month | Performances | Year | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Musical | 205909883 | 1882287 | 354478 | 15792740093 | 1488758 | 147858 | 170514 | 45237842 |
| 1 | Play | 43056274 | 618454 | 132291 | 2737985361 | 446950 | 53389 | 53878 | 16858645 |
| 2 | Special | 1731171 | 26064 | 5231 | 123844139 | 17289 | 2460 | 1716 | 679381 |
You can either call each one separately like we did at first or chain them all together at once like this. Either way works, but chaining is usually the preferred way to call all of these methods in order.
Now we can plot the grouped, summed data in a bar chart:
plt.bar(x="Type", height='Gross', data=df_groupby_type_sums)
plt.ylabel("Total Gross Revenue ($)")
plt.title("Gross Revenue by Show Type")
plt.show()